

|
|
Greg Kochanski |
|
In speech, it's fairly clear what is a word and what is not, but speech is more than just a string of words. The way you say the words matters, too. This is known as the intonation or the prosody of the speech. Intonation ( i.e. the pitch of speech) is a slippery thing. On one hand, changing the intonation of a sentence can make it mean different things, can change a statement to a question, or can help infuse a straightforward statement with irony or sarcasm. On the other hand, it is peculiarly difficult to attach names to intonation or to associate measurements of intonation with meanings. Even now, 20-30 years after routine measurements of intonation became practical and linguists and speech scientists began research on the topic, many basic issues remain unresolved.
We set out to attack perhaps the most fundamental issue in intonation research: does the mind interpret intonation (like words) as a sequence of discrete units or not? These units would be symbols of meanings, much as words are, but would be longer, as long as a phrase or sentence. Does intonation apply meaning in splashes of a few bold primary colours, or does it use a blended palette? Only one experiment has attempted to answer that question so far, a paper by J. Pierrehumbert and S. Steele in 1989. This small experiment had both limited statistical analysis and some methodological problems. Our experiment was designed to produce a more conclusive answer.
We set up an experiment where each subject played a version of Chinese Whispers with themselves. The game of Chinese Whispers (UK; Telephone in the US) captures much of the essence of language. In the game, players form a line or a circle, and a whispered sentence is passed along the chain. Between players, the whisper is a bit ambiguous because not all the sounds are clear. However, for each individual player, much of the ambiguity vanishes and a sentence is heard. Sometimes it is different from what the last person had in mind, sometimes it can be quite amusing, but the ambiguous sounds in the whisper always seem to be resolved into the nearest words in English that make sense.
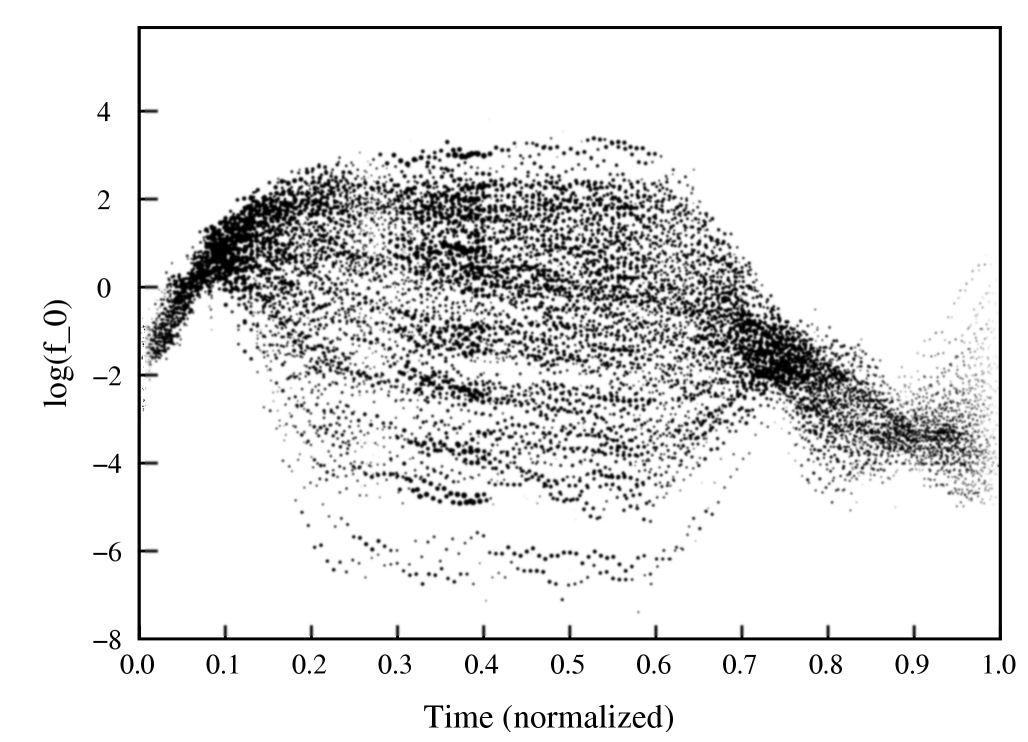
|
| Figure 1: The 100 different stimuli presented to the subjects. The vertical axis is the fundamental frequency of the speech (in semitones, relative to the subject's average frequency). We gave the subjects a wide range of different frequencies in the centre of the sentence, and also independently varied the frequency at the end of the sentence. |
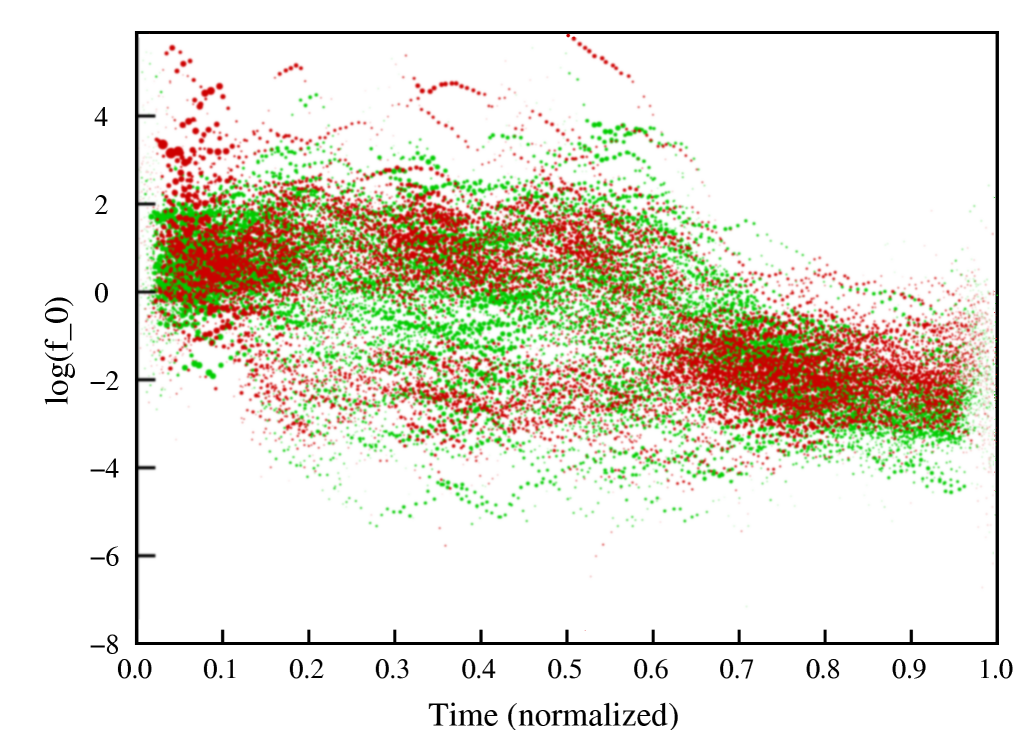
|
| Figure 2: Responses from the subjects. The first response (produced as a mimicry of one of the sentences shown above in Figure 1) is in green. The fourth response (where the subjects mimic themselves) for each sentence is shown in red. You see that by the fourth (red) response, the subject's responses separate into two branches in the first half of the sentence. The speech tends to be either high or low pitched, with relatively few responses at intermediate pitches, even though some of the the initial stimuli (Figure 1) were at intermediate pitches. The separation into branches is nearly complete in the red data, where the subject has been mimicking him/herself three times. The separation in the green data is incomplete; there are still a number of sentences that have a pitch in between the two branches. |
The slow convergence means that the mind doesn't remember just the "symbol" of a contour; it also stores a part of the acoustic detail. In fact, the results raise the possibility that the mind does not explicitly work with the symbols of intonation. Although the separate discrete symbols exist implicitly, as the endpoint of a series of repetitions, the mind may not automatically reduce a contour it hears to a symbol. This may explain some of the difficulty people have in putting different names to a particular kinds of intonation.
We thank the Oxford University Research Development Fund for support via grant RDF/1*181. A complete description of this work can be found at http://kochanski.org/gpk/papers/2005/2005mimicry.pdf .
| [ Papers | kochanski.org | Phonetics Lab | Oxford ] | Last Modified Fri Jul 8 00:05:17 2005 | Greg Kochanski: [ Mail | Home ] |